
Anne-Claire Brunet - Data scientist Kaduceo
Les services d’urgence ont de plus en plus de difficultés à faire face à l’afflux de patients qui ne cesse d’augmenter, et les risques de sur-engorgement sont une réelle menace pour la qualité des soins. Dans ce contexte, la prévision des admissions aux urgences constitue un enjeu de taille. Le déploiement d’un modèle prédictif pourrait permettre aux établissements de s’organiser en amont, et de mobiliser les ressources nécessaires pour répondre au mieux à la demande.
Cette problématique a déjà été abordée, mais le plus souvent, ce sont des modèles classiques d’analyse de séries temporelles (ARIMAX) qui ont été utilisés pour y répondre. Ces modèles font l’hypothèse que les relations entre les variables sont linéaires, ce qui peut s’avérer trop contraignant, voir irréaliste. Pour illustrer cette idée, nous pouvons prendre l’exemple des épisodes de canicule au cours desquels une recrudescence d’activité aux urgences peut être attendue. Dans ce cas, la relation entre la variable des températures et le nombre d’admissions n’est clairement pas linéaire: ce n’est pas l’augmentation des températures qui décrit un épisode de canicule, mais le fait que celles-ci stagnent à des niveaux élevés.
Une nouvelle approche : le deep learning
Pour s’affranchir de ces hypothèses, nous avons utilisé des techniques d’apprentissage profond. Ces réseaux sont capables de conserver en mémoire les observations passées et de modéliser leur impact sur le présent selon des schémas complexes et non linéaires. Notre objectif est donc de faire des prévisions qui soient les plus précises possible en intégrant dans le modèle un maximum d’information pouvant contribuer à anticiper un surcroît d’activité.
Avec les modèles d’intelligence artificielle (IA), il est tout à fait possible de construire ce type de modèles complexes, pour mettre en relation un grand nombre de variables de tout types (météo, qualité de l’air, événements culturels, trafic…).
0 ansd'observationsUn réseaux est défini à partir de différentes couches qui s’articulent les unes avec les autres selon une architecture qu’il faut définir, et qui va déterminer la qualité du modèle. Il n’existe pas de modèle préétabli et chaque cas d’usage nécessite de concevoir une architecture qui sera capable d’apprendre et de tirer profit de l’information qui lui est donnée en entrée. Le type de couches utilisées dans le réseau est fonction du type de variable en entrée. Pour la prévision des urgences, les données en entrée sont des données temporelles. Dans un réseau de neurone récurrents, ce sont les couches LSTM ou GRU «avec une mémoire» qui permettent de modéliser les relations entre les observations passées et futures. Toute la difficulté est de parvenir à définir une architecture de réseau qui soit optimale.
Un réseau n’est pas complètement intelligent… Mais il est capable d’apprendre en suivant les règles d’action que nous lui donnons.
En effet, il ne suffit pas d’ajouter de l’information en entrée pour augmenter la qualité des prévisions. Plus le modèle est complexe et plus il faut veiller à ce que les données soient correctement traitées à l’intérieur du réseau.
Acteurs hospitaliers
Intégrez simplement l'IA dans le pilotage de votre établissement
Découvrir notre solutionUn exemple concret :
L’exemple qui suit a pour objectif d’étayer l’importance de l’étape de conception du réseau. Nous avons construit trois modèles. Chacun de ces modèles cherche à faire une prévision à j+1 du nombre d’admissions aux urgences à partir des observations disponibles sur les quinze jours précédents.
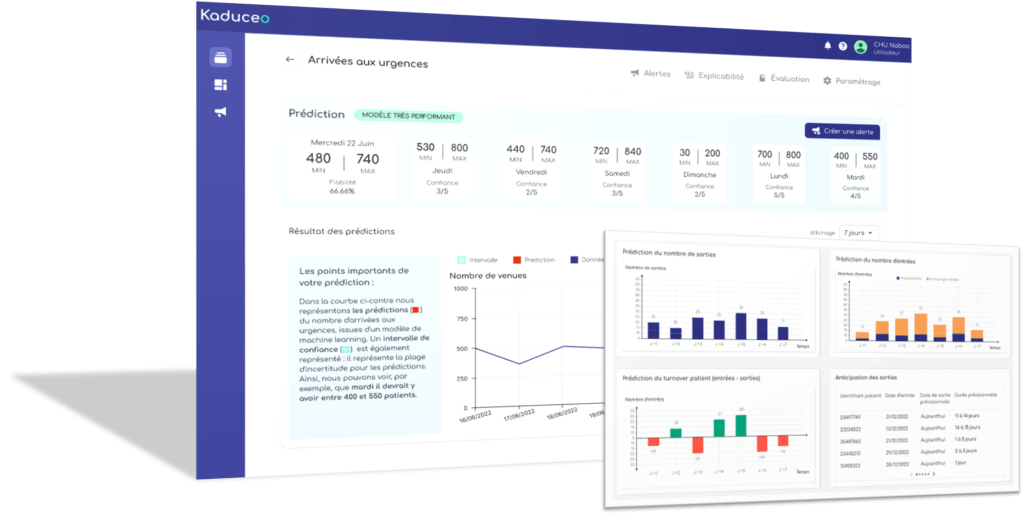
Un premier modèle (M1) reçoit en entrée les observations passées de la série du nombre journalier des admissions. Dans les deux autres modèles (M2 et M3), nous ajoutons de l’information sur les caractéristiques des jours (jour de la semaine, mois, jour férié, vacances scolaires), ainsi que des données météo (température min et max, taux d’humidité et mesure des précipitations).
Les variables en entrée pour M2 et M3 sont identiques, mais leur architecture est différente. Les modèles sont décrits sur la figure 1. Dans le modèle M2, toutes les entrées, nombre d’admissions, caractéristiques des jours et météo, sont présentées à une même couche GRU sur le réseau, tandis que dans M3, nous plaçons deux couches en parallèle: l’une pour le passé de la série du nombre d’admissions, et l’autre pour les données de météo et des caractéristiques de la période. En plus des couches de GRU, nous ajoutons en parallèle une couche dense qui reçoit en entrée les caractéristique du jour pour lequel nous faisons la prévision, c’est à dire j+1.
Figure 1 : Architecture des différents modèles
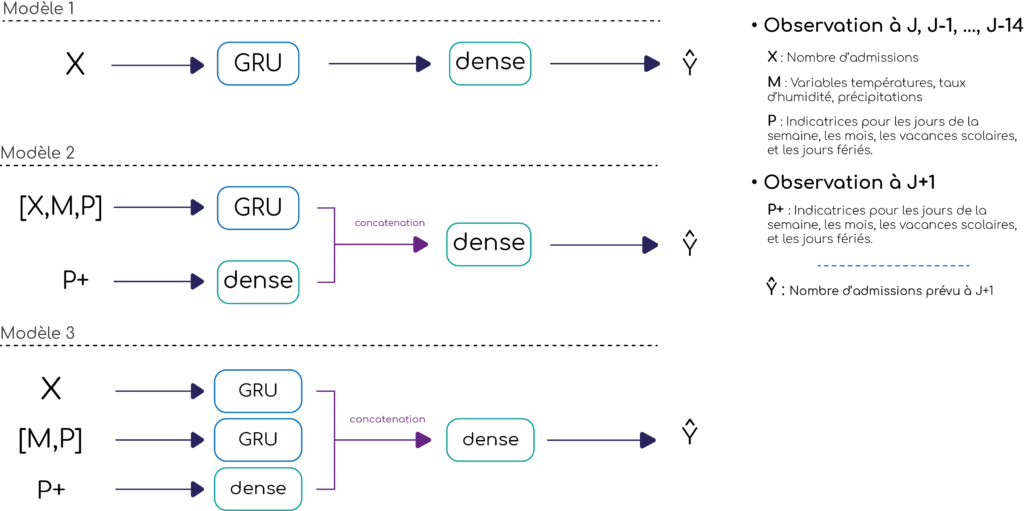
Nous avons entraîné les trois réseaux à partir des observations fournies par le Centre Hospitalier Intercommunal de Créteil (CHIC) sur une période de 7 ans, avec pour objectif de minimiser l’erreur absolue moyenne (MAE). Les évolutions des MAE sur les échantillons d’apprentissage et de validation, à chaque itération ou époque, sont représentées sur la figure2. Le modèle M1 est celui qui commet le plus d’erreurs sur l’échantillon d’apprentissage et c’est le modèle M2 qui en fait le moins. On voit cependant que M2 est difficilement généralisable, puisque c’est celui qui est le moins performant sur l’échantillon de validation. C’est le modèle M3 qui fait le moins d’erreurs sur l’échantillon de validation. On améliore ainsi les performances du modèle en positionnant des couches GRU en parallèle.
Figure 2 : Performance des modèles
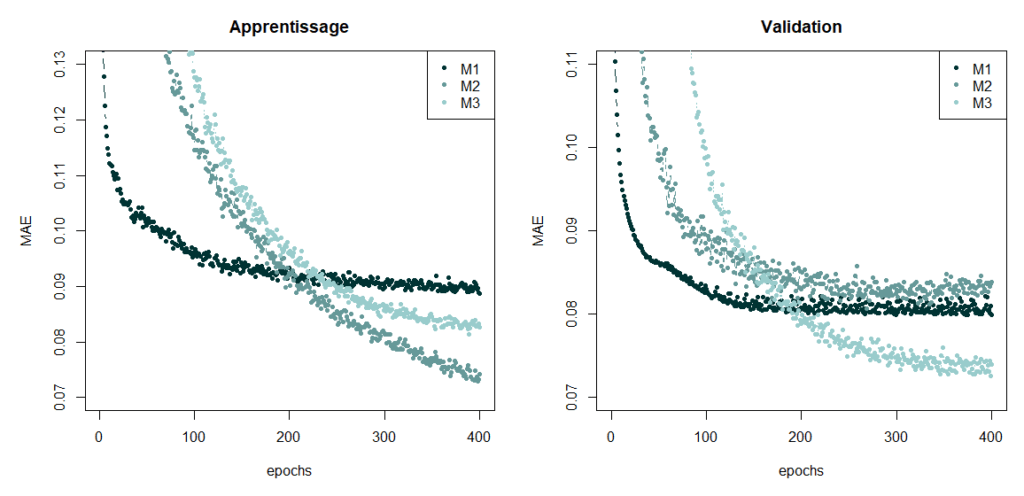
Les prévisions effectuées avec ce modèle sur un échantillon test (année 2017) et le pourcentage d’erreur pour chaque prévision sont représentés sur les figures 3 et 4. Sur l’année 2017, le nombre moyen journalier d’admissions est de 251. Notre modèle fait une erreur de 22 admissions par jour en moyenne, soit 9% du nombre moyen journalier d’admissions.
Figure 3 : Prévision sur un échantillon test
La recherche de performance
La performance du modèle dépend également du choix des différents paramètres du modèle: le nombre de couche, le nombre de neurones, les paramètres de régularisation pour lutter contre le sur-apprentissage, la taille des ensembles d’observations utilisés à chaque itération… En pratique, il n’est pas possible d’optimiser simultanément l’ensemble de ces paramètres. L’identification de paramètres optimaux est une étape délicate dans l’analyse. Il faut trouver un bon compromis entre la complexité du modèle et sa capacité à être généralisé. Autrement dit, si l’on crée un modèle trop complexe, en multipliant le nombre de couches et de neurones, le modèle fera très peu d’erreur sur l’échantillon d’apprentissage, mais ne sera pas performant sur un autre échantillon n’ayant pas servi pour l’apprentissage. C’est ce phénomène de sur-apprentissage qu’il est nécessaire de limiter.
Sur cet exemple nous présentons un modèle assez simple pour la prévision du nombre d’admissions aux urgences avec lequel nous parvenons quand même à avoir des performances assez satisfaisantes, mais pas suffisantes. Nous avons alors envisagé différentes pistes d’amélioration. L’objectif est de proposer un outil complet d’aide à la gestion dans le service des urgences. Nous développons actuellement un modèle capable de faire des prévisions à une semaine d’échéance pour chacun des différents domaines d’activité.
L’enjeu principal est de pouvoir fournir des prévisions suffisamment fiables pour pouvoir alerter les hôpitaux dans le cas où un pic d’activité est prévu.
Pour chaque domaine d’activité, nous cherchons à enrichir le modèle avec des variables qui peuvent avoir une influence sur le nombre d’admissions. Par exemple, pour pouvoir anticiper les épidémies de bronchiolite qui ont un impact sur l’activité dans le service des urgences pédiatriques, nous avons enrichi notre modèle avec des données de qualité de l’air.
Un outil de prédiction pour accompagner la prise de décision
L’avantage des modèles d’IA est qu’ils sont capables d’identifier des relations complexes pouvant exister entre les variables, et ils offrent la possibilité d’intégrer de nombreuses données explicatives. Leur principale limite est qu’ils sont assez opaques et difficiles à interpréter, dans le sens où il est difficile de comprendre a posteriori comment interagissent les différentes variables. Cependant, dans le contexte qui nous intéresse, cette limite n’est pas bloquante puisque le modèle est proposé à des fins organisationnelles et non médicales.
Nous ne cherchons pas à expliquer ce qui peut avoir un impact sur l’activité et de quelle manière, mais à proposer un outil capable d’alerter et de donner de la visibilité sur l’activité, et permettre ainsi de prévoir les ressources nécessaires.