
Elodie Escriva - Doctoral student in computer science
For several years, Artificial Intelligence (AI) and Machine Learning (ML) models have been used in many fields, from movie recommendations on online platforms to autonomous cars or medical robots. The use of AI has led to the development of many tools to assist humans, support many tasks, solve complex problems or assist in decision making. However, the risks inherent in an AI error have different impacts in different scopes of application.An error in a medical robot performing surgery will have a much greater impact than an error in recommending a film on a streaming platform. Model evaluation metrics such as accuracy, specificity or sensitivity are not always adequate to evaluate models against the real world. Indeed, these metrics are calculated on validation data that may be different from real-world data, making the metrics meaningless. [1]
To reduce errors and better understand the predictions made by AI, the explicability of AI models (XAI for "eXplainable AI") has emerged as a research field.
Explainability is defined as "the ability of a human to understand the cause of a decision" [2]
A highly explainable AI then provides the user with easily understandable predictions, increasing the user's confidence in the model.
Taxonomy of explainability methods
With the emergence of various explicability methods for machine learning prediction models, classifications emerged to characterise and classify these methods. The classification described by C. Molnar [3] has three characteristics:
- Intrinsic vs. Ad-hoc: explainability comes directly from the model through its simple structure or a method is applied to the model after training to analyse it
- Model-specific vs. Agnostic: the explainability method is applicable to specific classes of ML models or to all classes of models
- Global vs. Local: the method explains the behaviour of the entire model or individual predictions
There are many methods available to date and the above taxonomy allows us to describe two broad categories: intrinsically interpretable AI models (i.e. model-specific) and model-agnostic post-hoc explainability methods.
The intrinsically interpretable models
Among the intrinsically interpretable models, logistic and linear regressions and decision trees are the most common ML models. By studying the weights of each variable in logistic and linear regressions, it is possible to study the importance of each variable both in the overall model and for specific individuals. However, explanations may be counter-intuitive or difficult to understand in the case of correlated variables, for example. Decision trees are useful for solving this problem of regressions, thanks to their ability to represent interactions between attributes and non-linear relationships between attributes and explained variables. The interpretability of trees is mainly based on their natural ability to be represented graphically in nodes and edges. It is then sufficient to start from the original node and follow the edges through the thresholds to the subset of data of interest. The explanations are simple and general, the binary decisions are easily understandable and the trustworthiness of the explanations depends on the performance of the model.
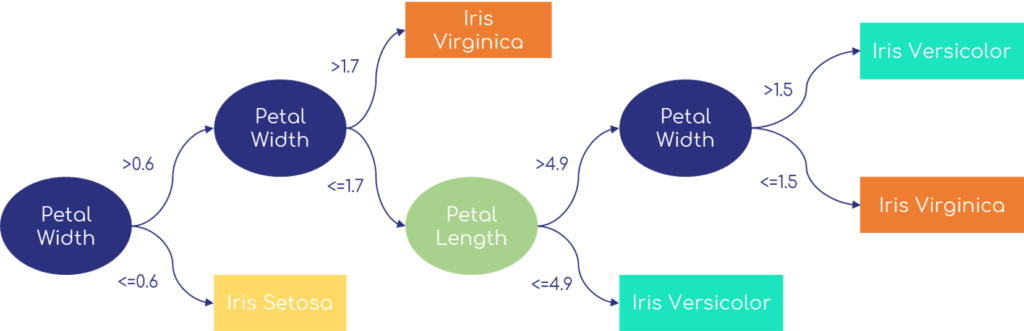
For example, in the case of Fisher's Iris (Figure 1), it is easy to understand the threshold values for the different categories. Following the graphical representation, Iris Virginica are flowers with :
- A petal width greater than 1.7cm (therefore greater than 0.6cm)
- OR a petal width between 0.6 and 1.5cm and a petal length greater than 4.9cm.
However, intrinsically interpretable models quickly show limitations for complex tasks as they form a restricted category of models compared to the existing set of models. Moreover, models must be kept simple to be easily explained since, for example, a list of 50 weights for a regression or a tree with 30 nodes would not be easily understandable by humans [3], [4].
Post-hoc agnostic methods
Post-hoc agnostic methods address this limitation of intrinsically interpretable models by separating the model from the explanations. This separation provides flexibility since explanations no longer depend on the class of the ML model and the ability of a model to be intrinsically interpretable is no longer a factor when choosing the best model to solve a task [1]. LIME [5] and methods derived from Shapley values [6] such as SHAP [7] or coalitional methods [8], [9], belong to the category of post-hoc agnostic methods.
Methods derived from Shapley values are based on the following collaborative game theory: in a collaborative game, players collaborate for a final payoff at a different level for each player and Shapley values allow a fair distribution of the payoffs to the coalition of players [3]. In the case of AI models, the players are represented by the attributes of the dataset and the payoff by the prediction. The method then calculates the influence of each attribute on the prediction for each individual in the dataset. In order to calculate these influences, SHAP is defined by unifying several methods such as LIME with Shapley values and also proposes specific methods for certain models (notably TreeSHAP for models based on decision trees). In parallel, the coalitional methods are a simplification of Shapley values through a calculation of the variables' correlation.
Advantages
- Individual and contrastive explanations
- Robust mathematical theory
- TreeSHAP and coalitional methods relatively fast
Disadvantages
- SHAP with slow computation times
- Potentially misinterpreted explanations
- Need for access to data and model
Example-based methods
Another way of representing explanations is through examples. The aim of these methods is to select existing or non-existing individuals in the dataset according to certain criteria, in order to provide information about the behaviour of the model. There are several methods based on examples, such as counterfactual examples [10], [11], prototypes & critics [12] or influential instances [13]. These methods are especially interesting in the case of images or text.
The counterfactual examples help to illustrate the changes needed in a given instance for the prediction to change. This method is based on the idea that a prediction is caused by the attributes of the instance and that a significant change in these attributes leads to a change in the prediction. For example, in the case of flat rent, counterfactuals to the instance "an unfurnished 60m² flat with 2 bedrooms and a balcony in a big city rents for €800" could be :
- An increase of 15m² in surface area increases the rent by €150
- Adding a fully functional kitchen increases the rent by €100
- Renting a furnished flat increases the rent by €300
This kind of explanation is easy for humans to understand because it focuses on a small number of changes in order to offer contrastive explanations. Counterfactual methods do not require access to the data or the model but only to the prediction function, making these methods attractive to companies wanting to protect their proprietary data and models [10], [11]. The major disadvantage is to limit the number of counterfactuals examples selected for a given instance, as there is theoretically an infinite number of them.
Limites

Research work on evaluating methods with specific metrics but not yet tested on large volumes of datasets [14]
Lack of a unique method of explicability that is perfectly optimal and applicable to all AI models

Problem of explanation comprehension and need to create interfaces to present them in sentences or graphs
More information : Interpretability vs Explicability
In several scientific publications scientific publications, the terms "Interpretability" and "Explicability "Explicability" are used without distinction. There However, there seems to be a fairly important one.
Interpretability seems to refer to purely mathematical notions and reflects the mathematical functioning of the model, as in the case of intrinsically interpretable models.
On the other hand, explainability refers to understanding why a model produces a particular result without understanding all the mathematical aspects, without opening the "black box".
A person without any knowledge of artificial intelligence can then understand the predictions and behaviour of the model. However, while interpretability follows reliable mathematical rules, explainability can be biased, unfair or even meaningless to humans because it does not follow real-world rules [15], [16].
Bibliography
[1] M. T. Ribeiro, S. Singh, et C. Guestrin, « Model-Agnostic Interpretability of Machine Learning », ArXiv160605386 Cs Stat, juin 2016, [En ligne]. Disponible sur: http://arxiv.org/abs/1606.05386
[2] T. Miller, « Explanation in artificial intelligence: Insights from the social sciences », Artif. Intell., vol. 267, p. 1‑38, août 2018, doi: 10.1016/j.artint.2018.07.007.
[3] C. Molnar, Interpretable machine learning. A Guide for Making Black Box Models Explainable. 2019. [En ligne]. Disponible sur: https://christophm.github.io/interpretable-ml-book/
[4] T. Hastie, R. Tibshirani, et J. H. Friedman, The elements of statistical learning: data mining, inference, and prediction, 2nd ed. New York, NY: Springer, 2009.
[5] M. Ribeiro, S. Singh, et C. Guestrin, « “Why Should I Trust You?”: Explaining the Predictions of Any Classifier », févr. 2016, p. 97‑101. doi: 10.18653/v1/N16-3020.
[6] E. Strumbelj et I. Kononenko, « An Efficient Explanation of Individual Classifications using Game Theory », J. Mach. Learn. Res., vol. 11, p. 1‑18, mars 2010.
[7] S. M. Lundberg et S.-I. Lee, « A Unified Approach to Interpreting Model Predictions », in Advances in Neural Information Processing Systems 30, Curran Associates, Inc., 2017, p. 4765‑4774. [En ligne]. Disponible sur: http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf
[8] G. Ferrettini, J. Aligon, et C. Soulé-Dupuy, « Improving on coalitional prediction explanation », présenté à Advances in Databases and Information Systems, Lyon, 2020.
[9] G. Ferrettini, E. Escriva, J. Aligon, J.-B. Excoffier, et C. Soulé-Dupuy, « Coalitional Strategies for Efficient Individual Prediction Explanation », Inf. Syst. Front., mai 2021, doi: 10.1007/s10796-021-10141-9.
[10] S. Wachter, B. Mittelstadt, et C. Russell, « Counterfactual Explanations without Opening the Black Box: Automated Decisions and the GDPR », ArXiv171100399 Cs, mars 2018, [En ligne]. Disponible sur: http://arxiv.org/abs/1711.00399
[11] S. Dandl, C. Molnar, M. Binder, et B. Bischl, « Multi-Objective Counterfactual Explanations », ArXiv200411165 Cs Stat, vol. 12269, p. 448‑469, 2020, doi: 10.1007/978-3-030-58112-1_31.
[12] B. Kim, R. Khanna, et O. O. Koyejo, « Examples are not enough, learn to criticize! Criticism for Interpretability », Adv. Neural Inf. Process. Syst., vol. 29, 2016, [En ligne]. Disponible sur: https://papers.nips.cc/paper/2016/hash/5680522b8e2bb01943234bce7bf84534-Abstract.html
[13] P. W. Koh et P. Liang, « Understanding Black-box Predictions via Influence Functions », ArXiv170304730 Cs Stat, déc. 2020, [En ligne]. Disponible sur: http://arxiv.org/abs/1703.04730
[14] R. El Shawi, Y. Sherif, M. Al-Mallah, et S. Sakr, « Interpretability in HealthCare A Comparative Study of Local Machine Learning Interpretability Techniques », in 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS), juin 2019, p. 275‑280. doi: 10.1109/CBMS.2019.00065.
[15] R. Draelos, « Grad-CAM: Visual Explanations from Deep Networks », Glass Box, mai 29, 2020. https://glassboxmedicine.com/2020/05/29/grad-cam-visual-explanations-from-deep-networks/
[16] N. Lauga, « IA et éthique : Comment comprendre son modèle ? ⚖ », Medium, févr. 25, 2019. https://medium.com/@nathan.lauga/ia-et-%C3%A9thique-comment-comprendre-son-mod%C3%A8le-ec217c92616d