
Jean-Baptiste Excoffier (Kaduceo), Elodie Escriva (Kaduceo), Julien Aligon (Université Toulouse-Capitole IRIT CNRS/UMR 5505), Chantal Soulé-Dupuy (Université Toulouse-Capitole IRIT CNRS/UMR 5505), Matthieu Ortala (Kaduceo)
Résumé
Les outils d’aide à la décision basés sur l’apprentissage automatique prédictif (ML pour Machine Learning) fournissent des prédictions brutes, parfois accompagnées d’explications individuelles. Cependant, il existe de la part des médecins un besoin de compréhension plus profonde de la situation globale sous-jacente afin de construire des protocoles médicaux qui s’adaptent au mieux aux principales typologies de patients.
Cette étude présente une nouvelle méthode pour construire une stratification des risques pour les soins de santé basée sur le ML, comprenant un modèle de risque prédictif et un clustering utilisant des explications locales. Un jeu de données en libre-accès a été utilisé pour démontrer l’efficacité de cette méthode qui a permis de correctement identifier les principaux sous-groupes de patients. De plus, leurs caractéristiques principales et spécificités ont été présentées de manière claire en utilisant le patient le plus représentatif de chaque groupe.
Les résultats indiquent que cette méthode pourrait aider les praticiens à ajuster et élaborer des protocoles pour améliorer les prestations de soins reflétant mieux le niveau de risque et le profil du patient.
Consulter l'abstractArticle accepté pour une présentation lors du "Medical Informatics Europe" organisé par le EFMI à Nice du 27 au 30 mai 2022
Introduction
Les outils d'aide à la décision basés sur des modèles prédictifs d’apprentissage machine (ML), fournissent souvent la prédiction seule sans aucune indication sur le processus de décision, ce qui soulève des inquiétudes quant à leur fiabilité et leur acceptation. Plusieurs méthodes ont donc été mises au point pour fournir des explications locales, également appelées influences, pour une prédiction individuelle (Linardatos et al., 2021). De plus, une tendance récente en ML est que les outils de prédiction doivent non seulement fournir des explications locales mais aussi permettre à l'utilisateur de contextualiser l'observation (Lundberg et al., 2020, Barda et al., 2020). Ce besoin est particulièrement élevé dans le domaine de la santé, où les médecins doivent relier un patient à un contexte plus global afin de fournir les soins les plus pertinents. La gestion des soins par la stratification des risques (abrégée en RS pour Risk Stratification) est ainsi couramment utilisée dans le domaine de la santé (Dera, 2019). Elle consiste à identifier des sous-groupes où les patients d'un même groupe ont un profil et un niveau de risque similaires. Néanmoins, aucune méthode n'a encore été développée qui tienne compte à la fois du pouvoir prédictif des modèles ML et de l'identification de tels sous-groupes homogènes. Cette étude propose une nouvelle procédure RS basée sur la modélisation prédictive ML, les méthodes d'explicabilité locale et le clustering, permettant aux médecins d'avoir une vision plus claire des différents profils des patients, également appelés typologies ou sous-phénotypes, afin d’ajuster les protocoles médicaux pour répondre au mieux aux besoins spécifiques de chaque groupe.
Etat de l'art
Les méthodes d’explications sont diverses afin de répondre à différents objectifs (Linardatos et al., 2021). Les méthodes locales et additives sont particulièrement intéressantes pour les données tabulées puisqu’elles fournissent pour chaque observation une valeur de l’influence qu’a eu chaque variable explicative sur la prédiction. Ainsi il est possible pour une observation individuelle (notion de locale) de quantifier l’influence de chaque variable. L’additivité indique que la somme des influences est égale à la prédiction ou à la prédiction moins un certain seuil. Ce type d’explications locales et additives est considéré comme étant le plus à même de correspondre à l’intuition humaine d’une explication (Linardatos et al., 2021). LIME et SHAP sont les méthodes d’explications locales et additives les plus utilisées (Linardatos et al., 2021), SHAP étant même préférable en terme d’efficacité et de stabilité des explications produites (ElShawi et al., 2021).
Méthode
La méthode proposée fonctionne à partir d’un jeu de données d’intérêt, contenant par exemple des patients, en indiquant s’ils sont atteints d’une certaine maladie (variable cible) ainsi que des informations médicales (appelées variables explicatives). Elle est divisée en trois parties principales :
Etape 1
Modélisation du jeu de données à l'aide d'un modèle prédictif ML, qui fournit pour chaque patient un niveau de risque, par exemple une probabilité d'avoir une maladie
Etape 2
Identification des facteurs de protection et de risque personnels à l'aide d'une technique d'explicabilité locale additive qui quantifie pour chaque patient l'influence de chaque variable explicative
Etape 3
Identification de sous-groupes de patients en fonction de leur état et de leur niveau de risque, en utilisant une technique de clustering sur les explications locales calculées à l'étape précédente.
Ensuite, une méthode de sélection d’observations peut être appliquée afin de fournir une vision claire des caractéristiques et spécificités de chaque groupe
Jeu de données
Le jeu de données en libre accès Acute Inflammations Data Set a été utilisé. Décrit dans (Czerniak and Zarzycki, 2003), il contient des informations cliniques sur les patients, la variable étant le fait qu’ils aient ou non une inflammation aiguë de la vessie urinaire, abrégé en IAVU. Les méthodes précises utilisées pour chaque étape sont les suivantes :
Etape 1
Un ensemble d'arbres stimulés basé sur l'implémentation de XGBoost a été utilisé comme modèle de risque prédictif ML (Chen and Guestrin, 2016). L’évaluation des performances s’est faite via une communément utilisée validation croisée de type 5-fold. Ainsi, tout le jeu de données est parcouru et chaque observation a une prédiction non-biaisée. De même, l’optimisation des hyperparamètres a été effectuée via une recherche exhaustive (GridSearch) avec une validation croisée interne de type 5-fold
Etape 2
La technique SHAP (SHapley Additive exPlanation) a été appliquée pour calculer des calculer des explications locales additives pour chaque patient (Lundberg et al., 2018).
Etape 3
L'algorithme K-Medoid a été utilisé pour le clustering sur les valeurs d'explication locale. Le nombre optimal de groupes a été sélectionné automatiquement avec le coefficient de Silhouette. L'algorithme K-Medoid présente également l'avantage d'être à la fois une technique de clustering et de sélection d’observations, puisqu'il peut fournir pour chaque sous-groupe identifié son patient le plus représentatif, c'est-à-dire le médoïde
Résultats
Les données comptaient 120 patients, dont 59 avec IAVU. Il y avait 6 variables explicatives, une quantitative (Température du patient) tandis que les cinq autres étaient toutes des variables binaires.
Concernant les performances du modèle, la précision était de 98,33%, la sensibilité de 96,72%, la spécificité de 100% et le score ROC AUC de 99,06%.
L’influence de chaque variable est représentée par la figure 1. Des Douleurs lombaires et une Température du patient plus élevée étaient associés à un risque plus faible d’IAVU, tandis que la Présence de nausées, des Douleurs mictionnelles, une Poussée d’urine et des Brûlure, démangeaisons et gonflement de l’urètre augmentaient tous le risque d’IAVU. Le nombre optimal de groupes en utilisant le score Silhouette était de 7.
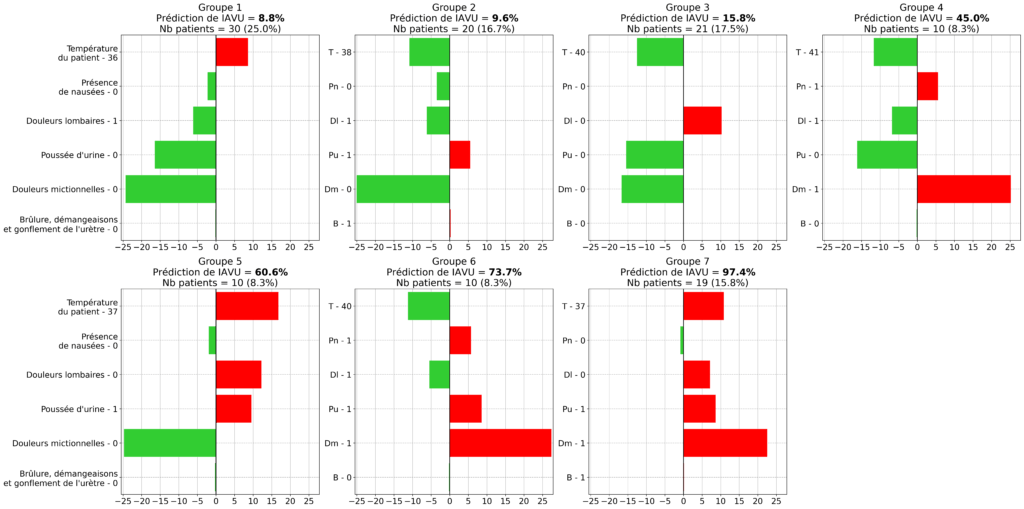
La figure 2 indique pour chaque groupe son patient le plus représentatif ainsi que ses influences associées.
La population était répartie assez uniformément entre les groupes, indiquant qu’il n’y avait pas de cas vraiment atypiques dans le jeu de données. Les groupes 1, 2 et 3 présentaient un niveau de risque IAVU très faible, avec un seul facteur de risque léger. Le groupe 4 présentait deux facteurs de risque, dont des Douleurs mictionnelles qui était un facteur de risque élevé. Le groupe 5 n’avait pas de Douleurs mictionnelles mais 3 autres facteurs de risque. Les groupes 6 et 7 présentaient le niveau de risque le plus élevé avec plusieurs facteurs de risque.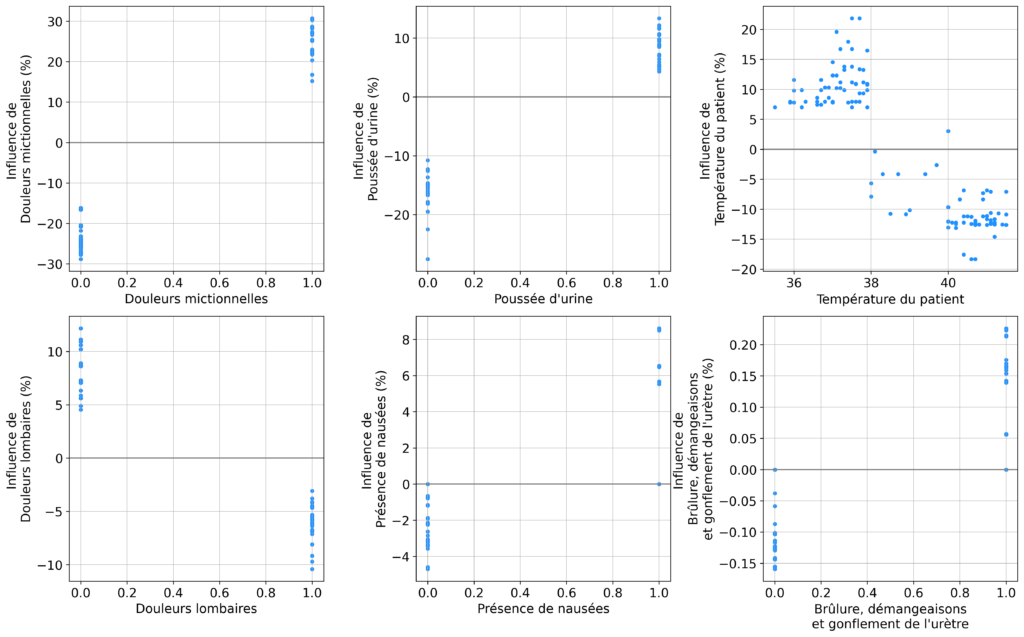
Discussion
Le modèle ML a montré d’excellentes performances sur le jeu de données de démonstration.
Les effets identifiés des variables explicatives étaient cohérents avec les indications médicales sur l’IAVU données dans l’article original (Czerniak and Zarzycki, 2003). Les groupes étaient différents en termes de niveau et facteurs de risque. En effet, même lorsque deux groupes avaient des niveaux de risque proches, ils différaient significativement en considérant les facteurs de risque. Par conséquent, la méthode proposée consistant en un clustering utilisant les explications locales a bien identifié les différents cas médicaux dans ce contexte (i.e. les différentes typologies de patients).
Cette catégorisation n’aurait pas été possible en utilisant uniquement les valeurs initiales du jeu de données. En effet, la combinaison de la modélisation ML et du calcul des influences des variables explicatives a permis de quantifier et d’identifier à la fois le niveau de risque et les facteurs de risque associés, qui ont ensuite été utilisés pour construire la stratification de risque (RS) finale.
Les résultats de cette étude indiquent que la nouvelle méthode proposée est une solide option à considérer lorsque l’objectif final de l’analyse des données est la construction d’un RS.
Cette étude s’est appuyée sur des articles comme (Lundberg et al., 2020, Barda et al., 2020) qui combinaient la modélisation ML et méthodes d’explicabilité pour obtenir une compréhension plus approfondie de la situation globale. Alors que ces articles se limitaient à l’analyse des effets des variables explicatives, la méthode de RS proposée a étendu l’utilisation des explications locales pour obtenir une vision plus efficace de la situation en identifiant les sous-groupes typiques existants qui diffèrent soit par leur situation (niveau de risque) soit par leur profil (facteurs de protection et de risque). De plus, l’accent mis sur le cas le plus représentatif de chaque groupe (i.e. médoı̈de) a permis une compréhension encore plus claire de la situation globale.
Cette nouvelle méthode peut donc aider les médecins à ajuster ou à créer des directives et des protocoles médicaux afin de répondre au mieux aux besoins spécifiques de chaque groupe. Cependant, la méthode proposée devrait être appliquée et évaluée dans des contextes médicaux plus complexes. Surtout lorsque les performances des modèles ne sont pas aussi élevées que dans cette étude, ce qui ne serait pas dû à une mauvaise construction du modèle mais plutôt à la limite intrinsèque du faible pouvoir de discrimination apporté par les informations utilisées.
Il s’agit donc du principal axe de travail futur afin d’identifier les points clés à améliorer pour que la méthode RS proposée puisse être adoptée pleinement et de manière fiable par les praticiens. Un autre axe de travail est d’évaluer l’intérêt de cette méthode dans d’autres domaines que le milieu médical. La méthode développée dans cette étude peut notamment être vue comme un cas particulier du raisonnement à partir de cas (Case-based Reasoning), régulièrement utilisé en recherches universitaires ou lors d’applications industrielles.
Bibliographie
- (Barda et al., 2020) Barda, N., Riesel, D., Akriv, A., Levy, J., Finkel, U., Yona, G., Greenfeld, D., Sheiba, S., Somer, J., Bachmat, E., et al. (2020). Developing a covid-19 mortality risk prediction model when individual-level data are not available. Nature communications, 11(1):1–9.
- (Chen and Guestrin, 2016) Chen, T. and Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794.
- (Czerniak and Zarzycki, 2003) Czerniak, J. and Zarzycki, H. (2003). Application of rough sets in the presumptive diagnosis of urinary system diseases. In Artificial intelligence and security in computing systems, pages 41–51. Springer.
- (Dera, 2019) Dera, J. D. (2019). Risk stratification: A two-step process for identifying your sickest patients. Family practice management, 26(3):21–26.
- (ElShawi et al., 2021) ElShawi, R., Sherif, Y., Al‐Mallah, M., & Sakr, S. (2021). Interpretability in healthcare: A comparative study of local machine learning interpretability techniques. Computational Intelligence, 37(4), 1633-1650.
- (Linardatos et al., 2021) Linardatos, P., Papastefanopoulos, V., and Kotsiantis, S. (2021). Explainable ai: A review of machine learning interpretability methods. Entropy, 23(1):18.
- (Lundberg et al., 2018) Lundberg, S. M., Erion, G. G., and Lee, S.-I. (2018). Consistent individualized feature attribution for tree ensembles. arXiv preprint arXiv:1802.03888.
- (Lundberg et al., 2020) Lundberg, S., Erion, G., Chen, H., DeGrave, A., Prutkin, J., Nair, B., Katz, R., Himmelfarb, J., Bansal, N., and Lee, S. (2020). From local explanations to global understanding with explainable ai for trees, nat. mach. Intell., 2, 56–67