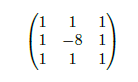Imagerie médicale : Architecture des réseaux neuronaux pour la classification d'images
Par Matthieu • 21 April 2021
Jean-Baptiste Excoffier - Data scientist
Les récents progrès des techniques d’apprentissage automatique ont permis ces dernières années une nette avancée dans l’analyse d’image, que ce soit dans un objectif de classification, de segmentation, de compression ou même de génération de nouvelles images fictives.
Cet article se concentre sur le sous-domaine qu’est la classification. A partir d’exemples où chaque image est associée à une catégorie, les modèles dits de Machine Learning apprennent à identifier des motifs spécifiques aux observations d’une même catégorie, ce dans l’objectif de distinguer au mieux les différents groupes.
Les méthodes les plus performantes se basent sur des réseaux neuronaux, qui font partie du Deep Learning, dont l’utilisation dans la recherche en imagerie médicale est maintenant largement répandue [1, 2] notamment pour l’aide au diagnostic précoce de cellules cancéreuses (cancer du sein), de maladies ophtalmiques (DMLA), ou bien l’estimation de la sévérité de l’atteinte pulmonaire pour des patients positifs à la Covid-19.
Nous allons présenter dans cet article les caractéristiques de ces modèles de réseaux neuronaux dans le traitement d’images, ainsi que l’évolution de leurs architectures.
Convolutions
La plupart des modèles d’apprentissage automatique de classification fonctionne avec des données tabulées. Une liste d’informations, appelées variables explicatives, est passée au modèle qui va les manipuler (association, pondération) dans le but de distinguer au mieux les différentes catégories.
Or, une image n’est pas une simple liste d’informations (en une dimension), mais bien un objet en deux ou trois dimensions. La première et deuxième dimension indiquent respectivement la largeur et la hauteur de l’image, tandis que la troisième dimension est ajoutée si l’image est en couleur.
Ainsi pour utiliser des modèles classiques de classification, l’image doit initialement être aplatie afin de la réduire à un objet à une dimension, une liste de pixels en l’occurrence.
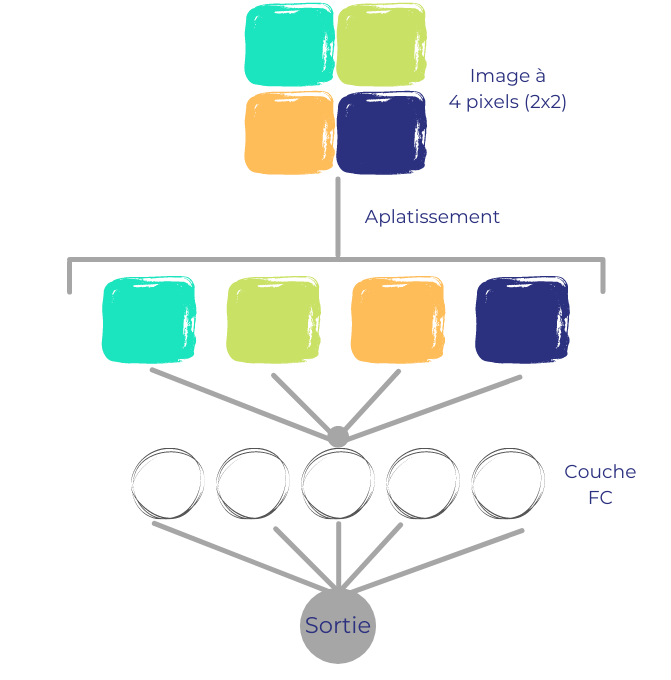
La figure 1 illustre le processus avec une image de quatre pixels et un réseau neuronal très simple, nommée Perceptron Multi-Couches (Multilayer Perceptron en Anglais).
Celui-ci est seulement composé d’une seule couche intermédiaire (FC pour Fully Connected) contenant cinq neurones. Après avoir aplati l’image en une ligne, chaque pixel est relié à tous les neurones. Chaque liaison est associée à un coefficient d’intensité indiquant le poids que donne le modèle à tel pixel pour tel neurone. Ce sont ces coefficients, aussi appelés poids ou paramètres, que le modèle va optimiser durant son apprentissage, en leur attribuant la valeur lui permettant de distinguer au mieux chaque classe les unes des autres.
La dernière couche (Sortie) rend pour chaque image la classe prédite par le modèle, ou la probabilité d’appartenance à chaque classe.
Figure 1 : Modèle simple de réseau neuronal
Néanmoins, le fait d’aplatir l’image ne permet pas de bien prendre en compte la distance, spatiale, entre les pixels. En effet, l’aplatissement rend plus complexe la compréhension de cette notion parle modèle, ce qui impact fortement ses performances. De plus, l’aplatissement produit une liste - un vecteur - de très grande taille. Notre premier exemple ne porte que sur une image 2×2 donc le vecteur contient 2×2 = 4 pixels, mais pour une image de taille habituelle, par exemple 300×300, cela revient à gérer un vecteur de 90 000 pixels. Il faut de plus multiplier le tout par 3 si l’image est en couleur(RGB).
Nous avons donc besoin d'une méthode capable d'extraire des informations à partir de la proximité spatiale des pixels ainsi que de leur intensité, résultant en une prise en compte des formes et des couleurs.
L’utilisation de filtre de convolution est justement une telle méthode. A partir d’une matrice de nombres, appelée filtre, matrice ou noyau de convolution (kernel ou mask en Anglais), cette technique modifie l’image en en faisant ressortir certaines zones ou certains aspects. Cette matrice de convolution, qui doit être plus petite que la taille de l’image que l’on souhaite traiter, se déplace ensuite sur la totalité de l’image, de gauche à droite et de haut en bas, en générant à chaque position un nombre qui sera donc un pixel de la nouvelle image engendrée par l’application du noyau convolutif.
Figure 2 : Exemple de filtre convolutif
Un exemple de filtre convolutif est donné par la matrice 2. Celui-ci a une dimension de 3 × 3 et permet de détecter les contours des objets ou des parties que l’image contient. Il est aussi utile de pouvoir diminuer la taille d’une image, notamment afin d’avoir moins de paramètres à gérer dans le modèle, diminuant de fait sa complexité.
Cela est possible en modifiant le pas (stride en Anglais) de l’opération de convolution, permettant de sauter un certains nombre de pixels au cours du déplacement du filtre convolutif. Si le pas vaut 1 alors l’image est de même dimension que l’originale, mais si le pas est à 2 l’image produite aura une hauteur et une largeur divisées par deux.
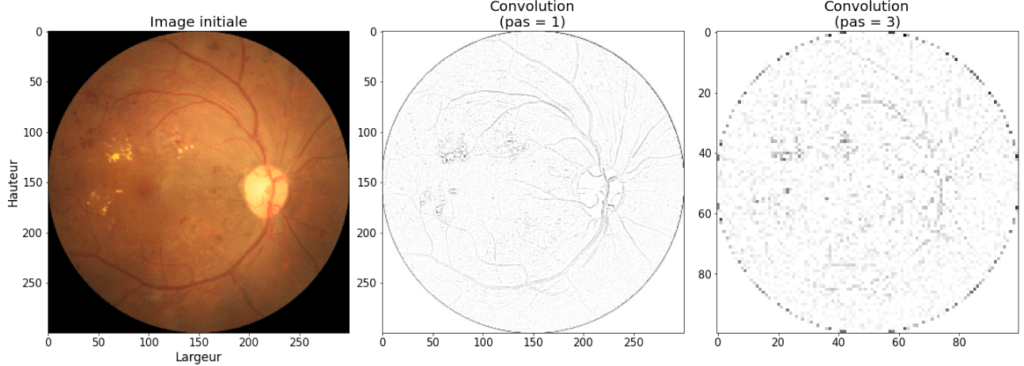
Prenons comme exemple une image provenant d’un examen ophtalmologique de fond d’œil dans le cadre de la détection précoce de la rétinopathie diabétique, atteinte oculaire qui est une aggravation du diabète [3]. Cette image est tirée du jeu de données open source nommé Eye-quality (eyeq) assessment dataset.
La figure 3 montre l’image originale d’un patient malade, ainsi que le résultat de l’application du filtre de convolution 2 avec deux pas différents. Avec un pas de 1 les contours des vaisseaux sanguins sont
bien détectés, tandis qu’un pas de 3 produit une image moins nette mais de taille inférieure (les axes indiquent les tailles).
Figure 3 : Convolutions sur une image d'examen ophtalmique
Ainsi nous avons une technique prenant bien en compte le côté spatial de l’imagerie. Bien que ce ne soit pas la seule technique utilisée dans les réseaux neuronaux actuels de traitement d’images -il y a notamment le regroupement ou pooling en Anglais-, la convolution reste la principale et surtout la seule possédant des coefficients (ou poids, paramètres), dont le modèle va pouvoir choisir les valeurs selon les données.
Par exemple, nous pourrions construire un modèle contenant le filtre 2, mais au lieu de choisir a priori les coefficients, le modèle apprendrait à optimiser ceux-ci afin d’avoir la meilleure précision possible pour la classification. Ce filtre aurait donc 3×3 = 9 poids à optimiser, auxquels il faut ajouter un poids commun (comme dans une régression linéaire ax + b). Pour les images en couleurs, il faut aussi multiplier le nombre de poids du filtre par 3 (canal RGB), ce qui pour un noyau convolutif de taille 3 × 3 donne en tout 3 × 3 × 3 + 1 = 28 paramètres.
Les différentes opérations de convolutions sont détaillées dans l’article [4].
Premières architectures
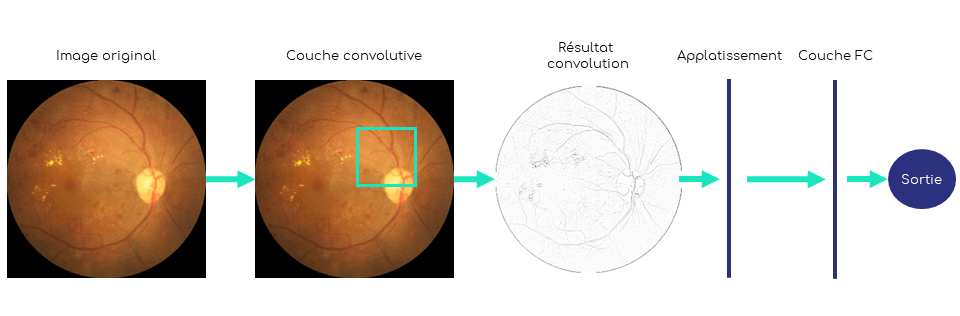
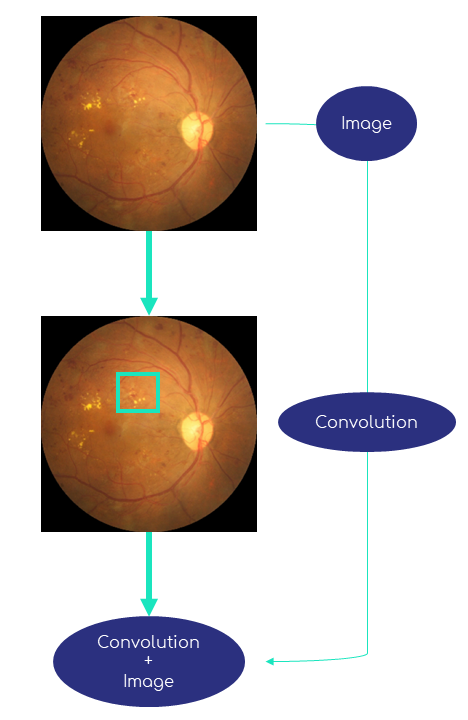
Une architecture très basique d’un modèle couplant réseau neuronal et convolution, appelée réseau neuronal convolutif (Convolutional Neural Network, abrégé en ConvNet ou CNN), peut par conséquent se composer d’une première couche avec un filtre convolutif afin de travailler une première fois l’image, puis un aplatissement de ce résultat suivi d’une couche complètement connectée (Fully Connected), pour finir avec la sortie du modèle qui est souvent un vecteur de probabilités (une pour chaque classe, le tout se sommant à 100%).
Le graphique 4 montre cette architecture basique. Ici la taille du filtre de convolution (le carré aux bords jaunes dans la deuxième image) est volontairement grossi, car en général celle-ci est relativement petite, de 1 × 1 à 5 × 5 pixels.
La première architecture de CNN est publiée en 1998 [5]. Celle-ci n’est guère plus complexe que la figure 4, puisqu’elle se compose seulement de deux couches convolutives suivies de trois couches complètement connectées. Ce modèle d’environ 60000 paramètres, nommé LeNet-5, fût appliqué à de la reconnaissance de chiffres dans les chèques bancaires et code postaux.
Néanmoins, les faibles capacités des ordinateurs de l'époque empêchaient un bon entrainement ainsi que l'utilisation de modèles lus complexes, ie. plus profonds car comportant plus de couches.
Figure 4 : Exemple simple de réseau neuronal convolutif
Il a donc fallu patienter jusqu’en 2012 pour constater une véritable percée dans la complexité des réseaux convolutifs, avec l’article [6] présentant le modèle AlexNet. Bien que peu différent en substance du LeNet-5, ce nouveau modèle est plus profond et contient beaucoup plus de paramètres, environ 12 millions.
En 2014, le modèle VGG-16 [7] voit une hausse considérable de la profondeur -13 couches convolutives contre 5 pour AlexNet- donc du nombre de paramètres à entraîner (138 millions).
Les modèles étaient par conséquent devenues très lourds, les chercheurs jouant principalement sur la nouvelle et grande capacité des ordinateurs à pouvoir gérer ces énormes réseaux neuronaux. Dès lors, les nouveautés allaient concerner l’amélioration de l’efficacité de l’architecture et non plus une simple augmentation brute du nombre de paramètres.
Architectures Inception
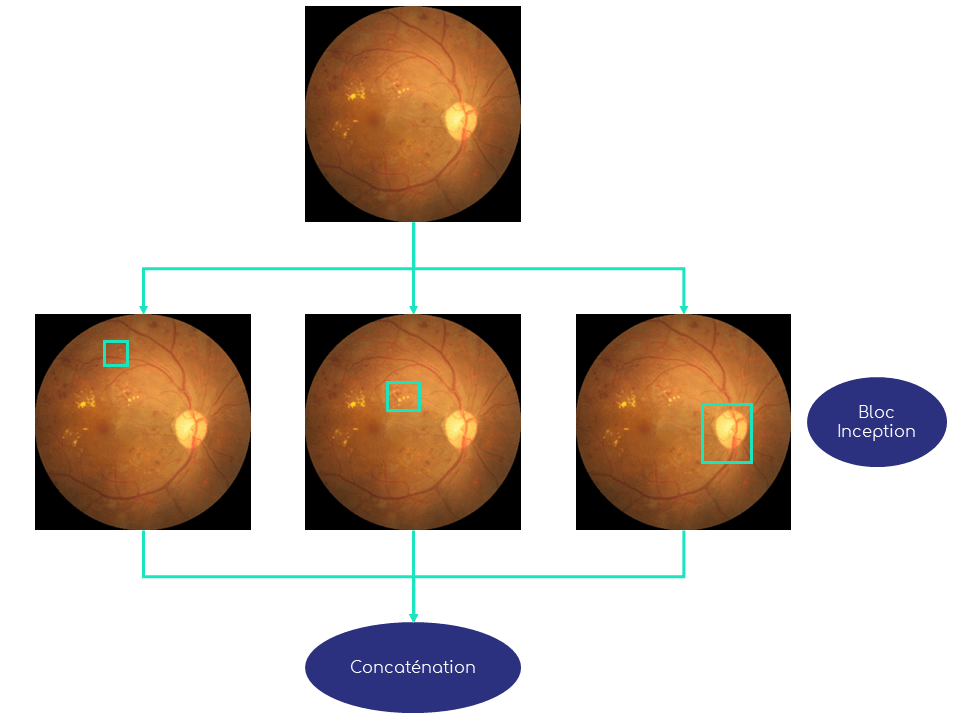
Une façon d’améliorer les performances des réseaux neuronaux fût de travailler non plus simplement sur la profondeur, mais aussi sur la largeur. Alors qu’auparavant les couches convolutives ne faisaient que se suivre l’une après l’autre, le modèle Inception-V1 publié dans l’article [8] en 2014 utilise des filtres de convolutions mis côte à côte dans des blocs dits Inception.
Chaque bloc contient par conséquent plusieurs convolutions de plusieurs dimensions, ce afin d’extraire des informations de différentes tailles. Les petits filtres convolutifs se focalisant sur des zones réduites de l’image, les filtres de plus grande taille captant des informations plus globales.
Un exemple de bloc Inception est présenté dans la figure 5. L’image, ou la couche précédente, est traitée en parallèle par des filtres convolutifs de différentes tailles : carrés bleu, rouge et violet, dont les tailles sont ici exagérées pour bien les rendre visibles, les dimensions des filtres étant souvent au maximum de 7 pixels de côté. Ensuite les différentes informations sont concaténées pour être passées d’un seul tenant à la couche suivante.
En 2015 est publiée une amélioration significative de Inception-V1, nommée Inception-V3 [9]. Les avancées portent principalement sur la factorisation des filtres convolutifs, en décomposant par exemple un filtre n×n en deux filtres : le premier de dimension 1×n suivi d’un filtre de taille n×1.
L’architecture Inception a grandement amélioré les performances des modèles tout en réduisant le temps d’apprentissage, notamment via la diminution du nombre de paramètres à optimiser : seulement 5 millions pour Inception-V1 et 25 millions pour Inception-V3, alors que VGG-16 contenait lui 138 millions de neurones. Néanmoins des problèmes persistaient pendant l'apprentissage, que les architectures suivantes vont fortement aider à corriger.
Architectures résiduelles
Figure 6 : Exemple de bloc Résiduel
L’une des problématiques majeures lors d’un entraînement d’un réseau neuronal était à l’époque la disparition du gradient (Vanishing Gradient en Anglais). L’entraînement est itératif : à chaque étape les valeurs des paramètres (ou poids, eurones) sont ajustées afin d’améliorer la performance du modèle. A chaque valeur initiale est ainsi ajoutée son gradient, indiquant la direction (gradient positif ou négatif) et le niveau d’ajustement nécessaire pour minimiser une fonction d’erreur. Sauf que régulièrement, ce gradient peut être égal à zéro, empêchant une réelle mise à jour des paramètres. Cela peut survenir après un bon nombre d’itérations, ce qui est alors normal et correspond à la fin de l’apprentissage puisque le réseau ne parvient plus à tirer de nouvelles informations pertinentes des images pour s’améliorer. Mais la disparition du gradient pouvait aussi survenir très rapidement, après quelques étapes, ce qui est alors un problème car provenant seulement d’une erreur numérique.
De plus, l’idée répandue à l’époque était qu’augmenter la profondeur d’un modèle améliorait automatiquement ses performances. Or, cela ne se traduisait pas en pratique puisque certains modèles moins complexes parvenaient à battre des modèles plus profonds...
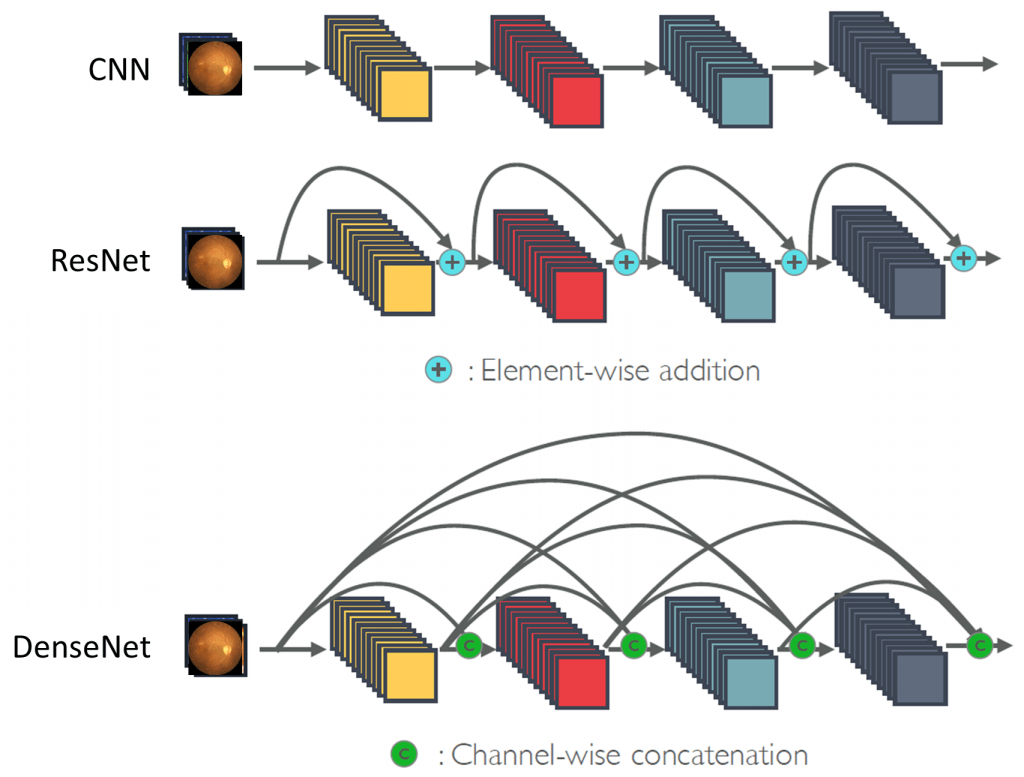
En 2015 sont introduits les réseaux résiduels, ResNet, dans l’article [10]. Leur particularité est qu’à chaque bloc, l’entrée est redistribuée à la sortie, comme le montre la figure 6. Ainsi le modèle apprend uniquement les effets de la convolutions, sans que cela ne dépende de l’entrée initiale, permettant une meilleure généralisation et efficacité, d’où le terme résiduel puisque l’apprentissage se fait sur la différence entre l’entrée et la sortie (donc le résidu) et non plus sur la sortie pure. De plus, le problème de disparition du gradient est très souvent évité avec cette architecture.
Plusieurs améliorations de ces réseaux résiduels ont été apportées depuis. Une approche combinant les architectures Inception et Résiduelle est d’abord proposée en 2016 [11] (Inception-ResNet), puis en 2017 [12] (ResNeXt).
Un autre axe d’amélioration est apporté par les modèles dits dense (DenseNet), dont une première version est publiée en 2017 [13]. Celle-ci ne reprend pas les blocs Inception, mais pousse au maximum le concept de l’architecture résiduelle. Alors que dans cette dernière, une seule liaison est ajoutée par bloc convolutif, un bloc Dense transmet quant à lui son entrée à tous les blocs suivants, comme montré dans la figure 7.
Cette architecture est à ce jour l’une des plus performantes, avec les Inception-ResNet [14].
Figure 7 : Comparaison des architectures : Convolutive simple, Résiduelle et Dense
Conclusion
L’analyse automatique d’images médicales, notamment dans un objectif de classification, a connu de nets progrès ces dernières années. La hausse des capacités de calculs ainsi que l’amélioration des méthodes principalement basées sur du Deep Learning, dont nous avons décrit les nombreuses évolutions ([15]) dans cet article, ont permis une augmentation significative de la précision des modèles de classification automatique, laissant de plus en plus envisager leur utilisation dans un réel cadre clinique afin d’assister les praticiens, particulièrement pour l’aide à la détection précoce de maladies.
Néanmoins, certaines problématiques concernant de tels modèles sont régulièrement soulevées, comme la fiabilité et la cohérence de ceux-ci. En effet, un modèle même performant peut pour une prédiction s’appuyer majoritairement sur des zones de l’image étant estimées comme peu voire pas cliniquement pertinentes par les médecins. Cela peut arriver lorsque le modèle s’est basé lors de son apprentissage sur des images contenant des artefacts plus présents dans une catégorie qu’une autre.
Par conséquent, il est indispensable de mieux comprendre le fonctionnement des réseaux neuronaux, notamment pour un diagnostic individuel, en visualisant les zones considérées par le modèle comme étant les plus importantes dans sa prise de décision.
De nombreuses techniques répondant à cette problématique, regroupées sous la notion d’explicabilité (aussi nommée interprétabilité dans certains cas), ont été développées ces dernières années. L’article suivant décrit l’état de l’art de ce domaine, et son utilisation en imagerie médicale.
Références
[1] G. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi, M. Ghafoorian, J. A. Van Der Laak, B. Van Ginneken, and C. I. Sánchez, “A survey on deep learning in medical image analysis,” Medical image analysis, vol. 42, pp. 60–88, 2017.
[2] S. K. Zhou, H. Greenspan, C. Davatzikos, J. S. Duncan, B. van Ginneken, A. Madabhushi, J. L. Prince, D. Rueckert, and R. M. Summers, “A review of deep learning in medical imaging : Imaging traits, technology trends, case studies with progress highlights, and future promises,” Proceedings of the IEEE, 2021.
[3] “Rétinopathie diabétique - snof.” https://www.snof.org/encyclopedie/r%C3% A9tinopathie-diab%C3%A9tique. Accessed : 2020.
[4] V. Dumoulin and F. Visin, “A guide to convolution arithmetic for deep learning,” arXiv preprint arXiv :1603.07285, 2016.
[5] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
[6] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, pp. 1097–1105, 2012.
[7] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv :1409.1556, 2014.
[8] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1–9, 2015.
[9] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern
recognition, pp. 2818–2826, 2016.
[10] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
[11] C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31, 2017.
[12] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1492–1500, 2017.
[13] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4700–4708, 2017.
[14] S. Bianco, R. Cadene, L. Celona, and P. Napoletano, “Benchmark analysis of representative deep neural network architectures,” IEEE Access, vol. 6, pp. 64270–64277, 2018.
[15] A. Khan, A. Sohail, U. Zahoora, and A. S. Qureshi, “A survey of the recent architectures of deep convolutional neural networks,” Artificial Intelligence Review, vol. 53, no. 8, pp. 5455–5516, 2020.